
Tag2Text is an efficient and controllable vision-language model with tagging guidance.
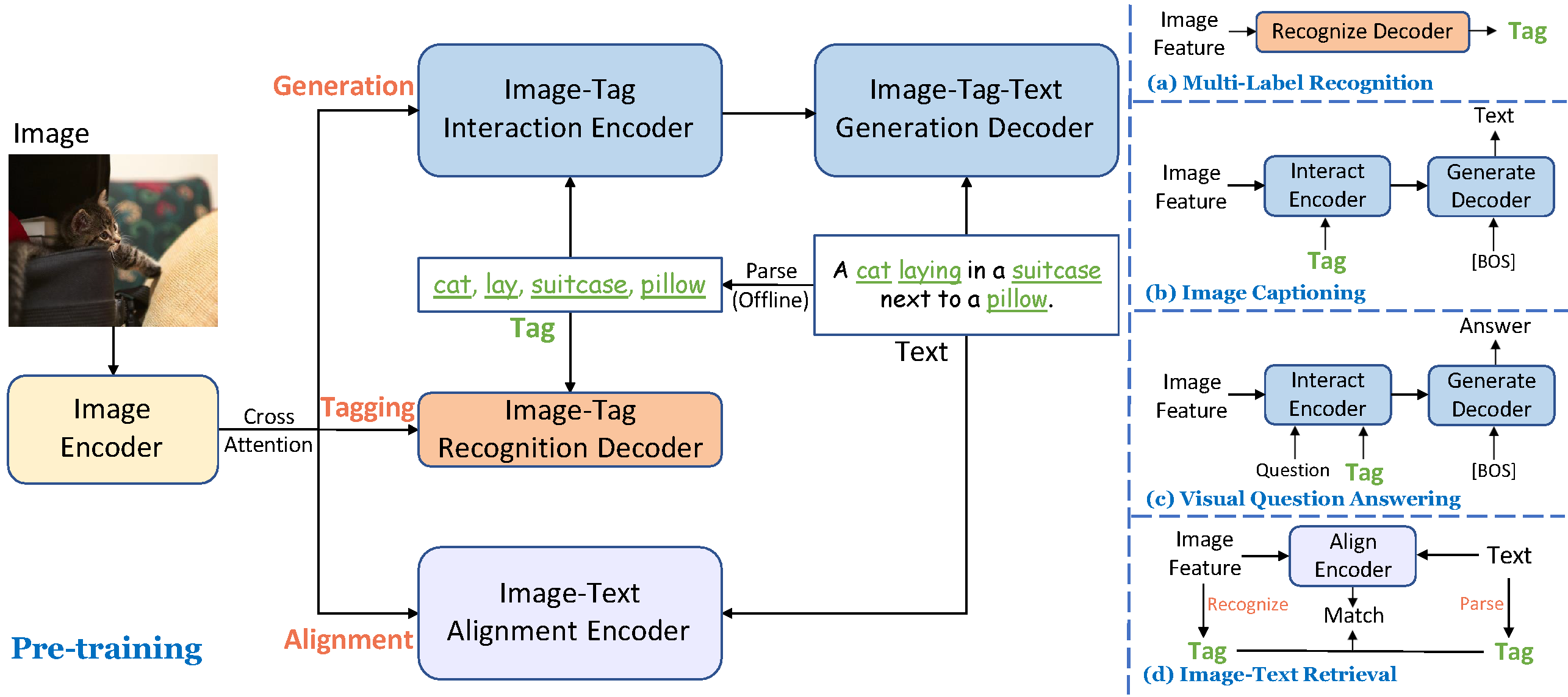
Tag2Text integrates recognized image tags into text generation as guiding elements (highlighted in green underline), resulting in the generation with more comprehensive text descriptions. Moreover, Tag2Text permits users to input desired tags, providing the flexibility in composing corresponding texts based on the input tags.

Tag2Text provides tags as additional visible alignment indicators (highlighted in green underline).

@article{huang2023tag2text,
title={Tag2Text: Guiding Vision-Language Model via Image Tagging},
author={Huang, Xinyu and Zhang, Youcai and Ma, Jinyu and Tian, Weiwei and Feng, Rui and Zhang, Yuejie and Li, Yaqian and Guo, Yandong and Zhang, Lei},
journal={arXiv preprint arXiv:2303.05657},
year={2023}
}